商標も意外と分かってるChatGPT
いつも特許情報分析の話ばかりしていますが、弁理士なのでたまには商標の話もしてみます。
ChatGPTは英語圏の情報を主に学習しているため日本の独自の制度には詳しくなく聞いても教えてもらうことはできない場合が多いです。特許分類であればIPCやCPCは詳しいけどFIやFタームは分かりません。
じゃあ商標はということで、商標であれば「区分」はグローバルな制度なのでわかりそうですね。
ということで試しに最近X社になったツイッター社の業務の区分について聞いてみます。
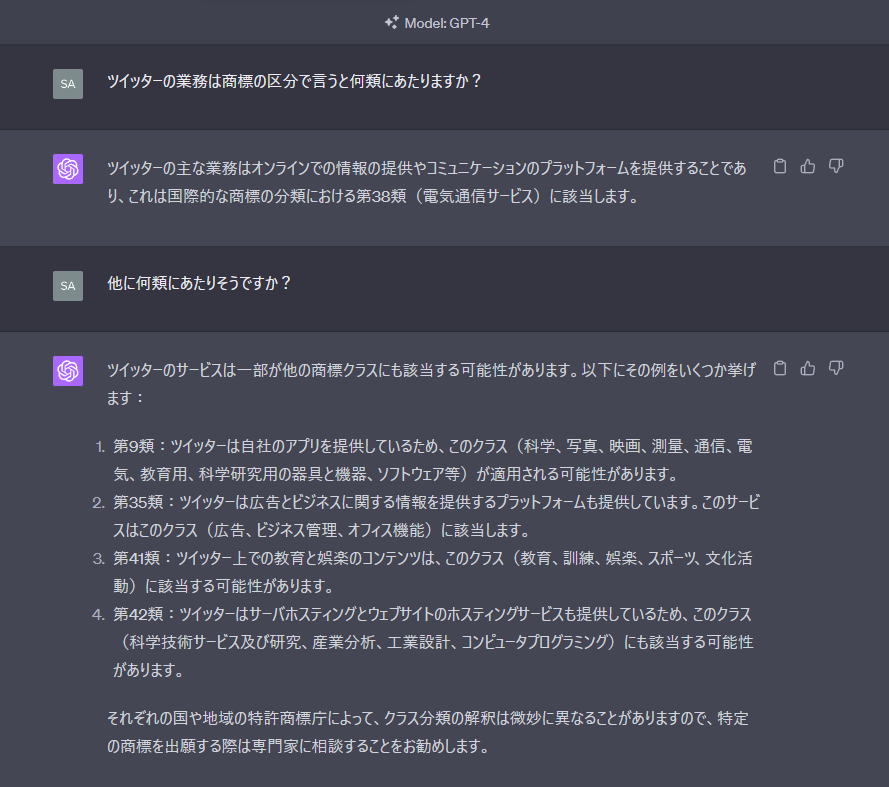
第38類、第9類、第35類、第41類、第42類の5つの区分が挙げられました。
答え合わせをしてみます。
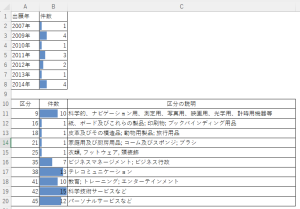
件数が多い順に、第42類、第38類、第45類、第9類、第41類、第35類などで出願がされているようです。
ChatGPTが提案してきた5つ全ての区分について実際に出願しているようです。回答は全て正解です。凄いですね。
特許分類でも、ある技術について関連するIPCを教えてと聞けば教えて貰えますが商標でも同じように区分については理解していることが確認できたので、出願を検討しているときに区分のアタリをつける使い方も良さそうです。
例えば、Twitterのような著名な会社でない会社の場合には、会社の概要をプロンプトで説明したりCode Interpreterで有価証券報告書などの会社情報を読み込んで、この会社の業務と出願すべき区分みたいな聞き方をしてもよさそうです。こうやって出願する区分について検討すると抜け漏れが防止できそうでよさそうです。プロンプトを複数回読み込んで複数回の回答をさせるのもよいですね。
逆に、日本特有の分類であり区分を細分化した「類似群コード」はFIやFタームと同じく分からないようです。
ついでに、検索結果のリストの部分の情報を使ってCodeInterpreterでグラフ化してみましょう。J-platpatでは検索結果がグラフ化されなくて不便だなといつも思っています。
出願年別と区分別の部分の2行をコピペしてグラフ化をお願いしてみます。
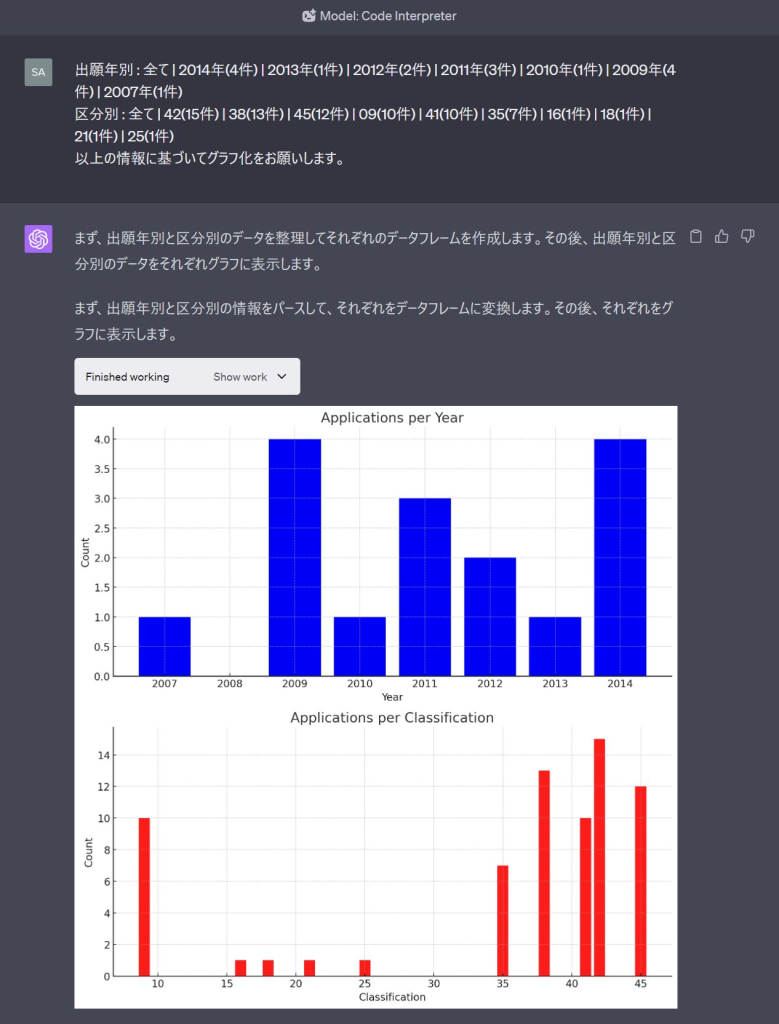
こんなに簡素な指示とコピペだけでグラフが描けるのはすごいですね。
もちろんエクセルに取り込んで自分でグラフ化すればもっと分かりやすい図は描けますし、出願件数に少数以下の数字はないから0.5刻みにしなくていいとか、分類は出願のある類の数字だけでいいとかツッコミどころはありますけど、細かい話です。
せっかくこんな便利なツールがあるのですから、みなさんもどんどん使って業務を改善していきましょう。
今回は以上です。