Code interpreterが特許情報分析でもガチでヤバイ件
ここ数日YouTubeやTwitterを賑わしているChat GPT-4のCode interpreter機能(ユーザがデータをアップロードしつつ目的に応じたプログラムを自動生成させ処理する機能)で分析してみた事例の紹介です。なお、Code interpreter機能は先週末(7/7)に利用可能になった機能です。
簡単なテストの結果として、小規模のデータで簡単なクロス集計してグラフ化するだけならもうChatGPTに任せた方がよさそうな気がしました・・・(汗)
以下で工程を説明します。
分析に使ったデータは、昨日の投稿で被引用件数のグラフの描き方を説明するのに使ったBYD社の出願なんですが、以下から入手できます。
Lens Patent Search: applicant.name:("BYD CO LTD")
私はLens.orgでアカウントを登録していないので無料ユーザーがダウンロードできる上位1000件まで入手しまして
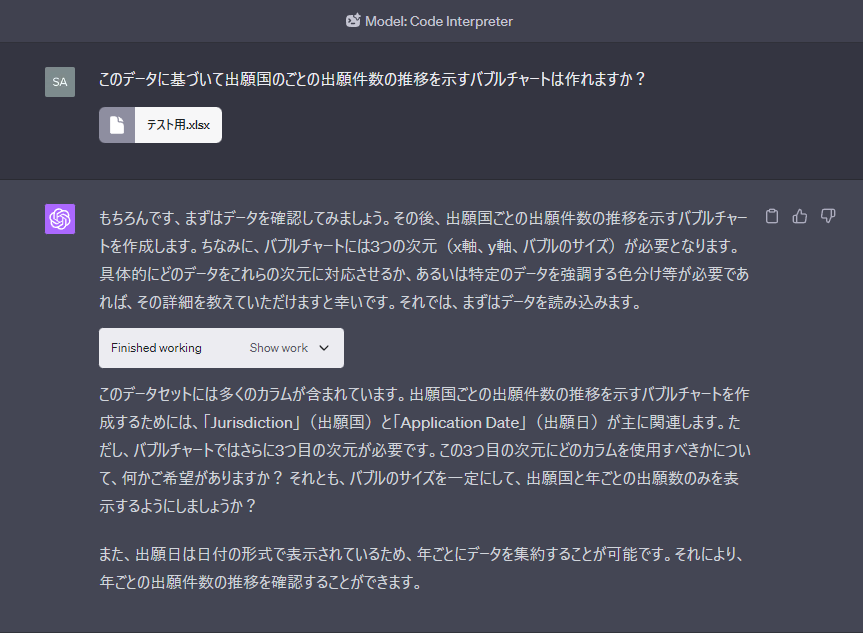
まず、このデータをCode interpreterに投げ込んでみます。回答を見る限りかなりいけそうな感じがします。
条件を細かく設定してくれと言われるのでグラフの仕様を簡単にコメントしてみます。
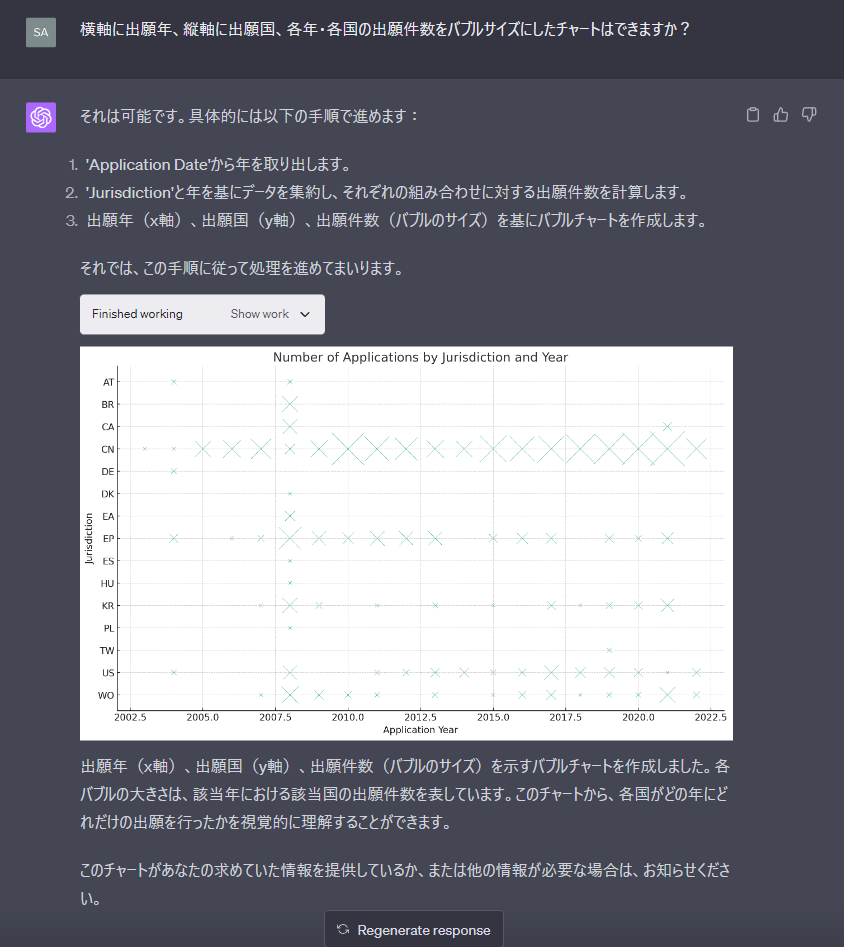
すると・・・何これこんな集計がいきなりできるの・・・!簡単すぎっ!
とはいえ、×だと分かりにくいのでバブルを丸に変えてもらうようにお願いします。
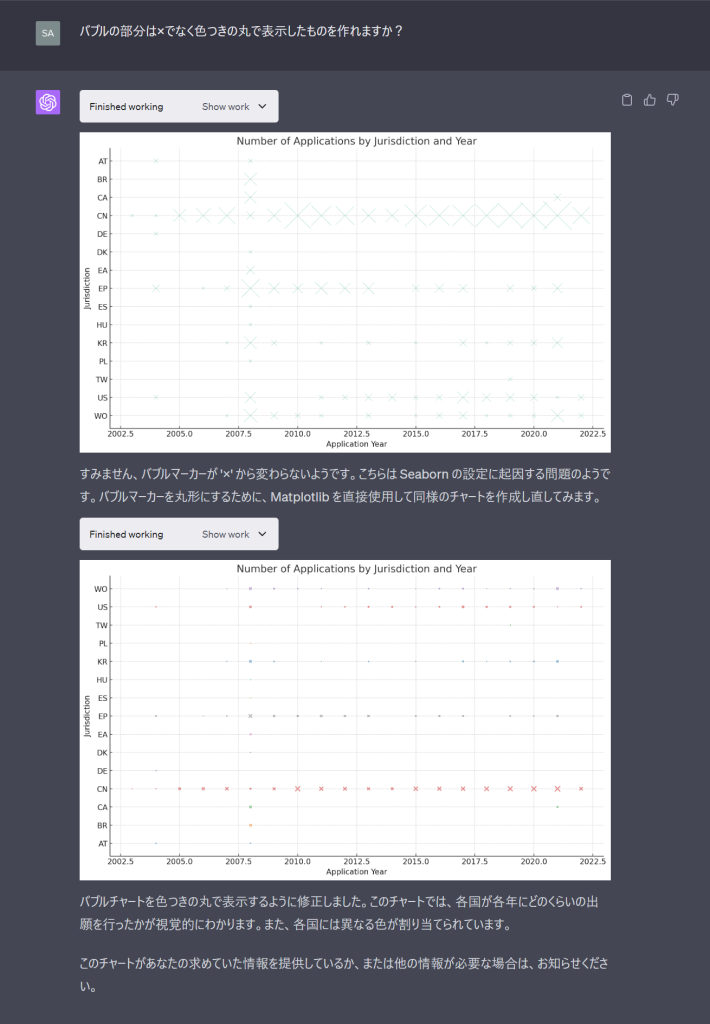
使っているpythonの仕様なのかバブルを丸にはしてもらえなそうです。それじゃあということで四角形にしてもらいます。
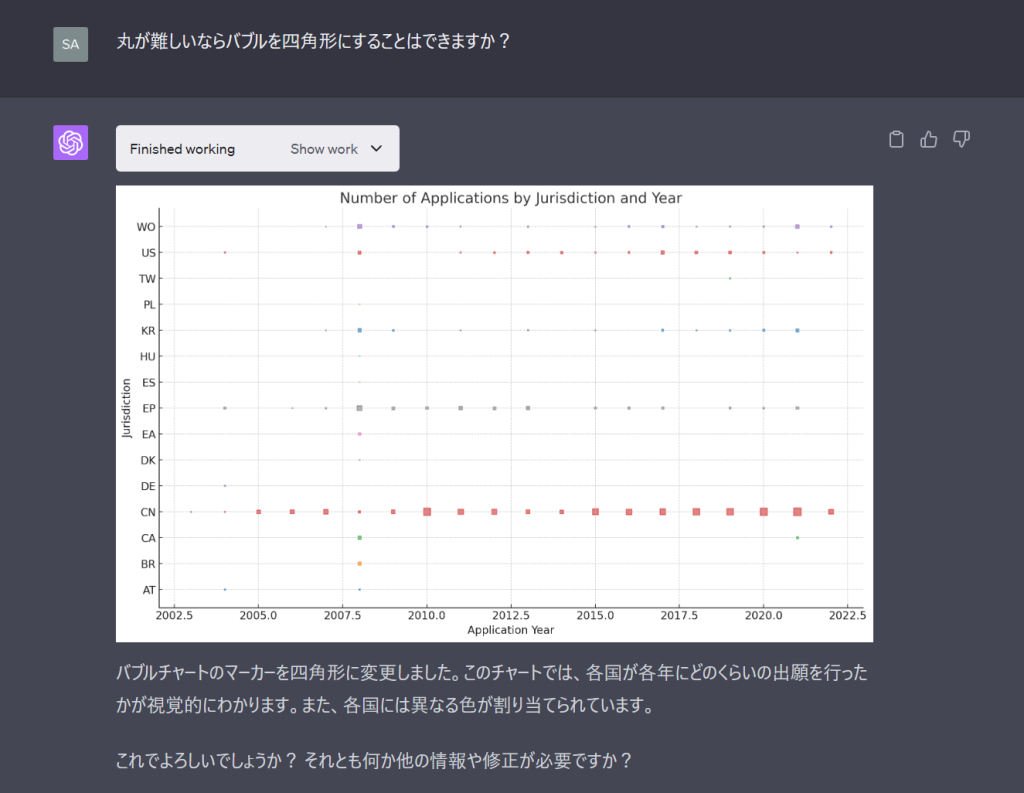
おー!概ねよさそうです。ここまでできるとなるともうちょっと欲張りたいですよね。ということでお願いを追加します。
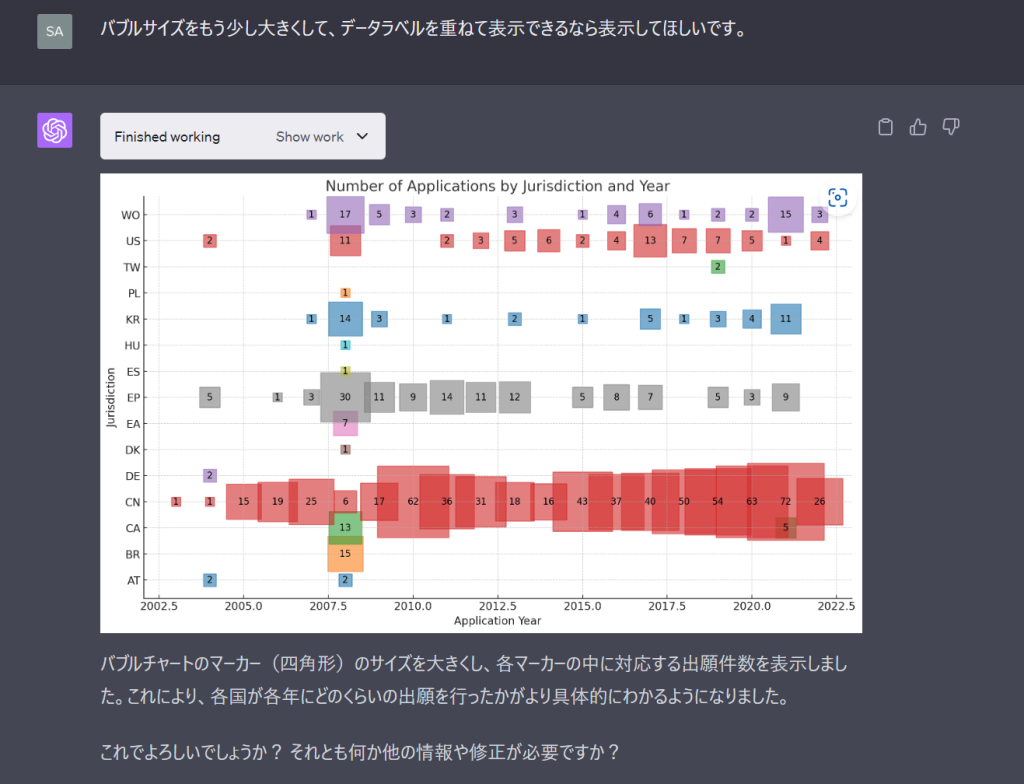
ここまでできるならもういっちょ!
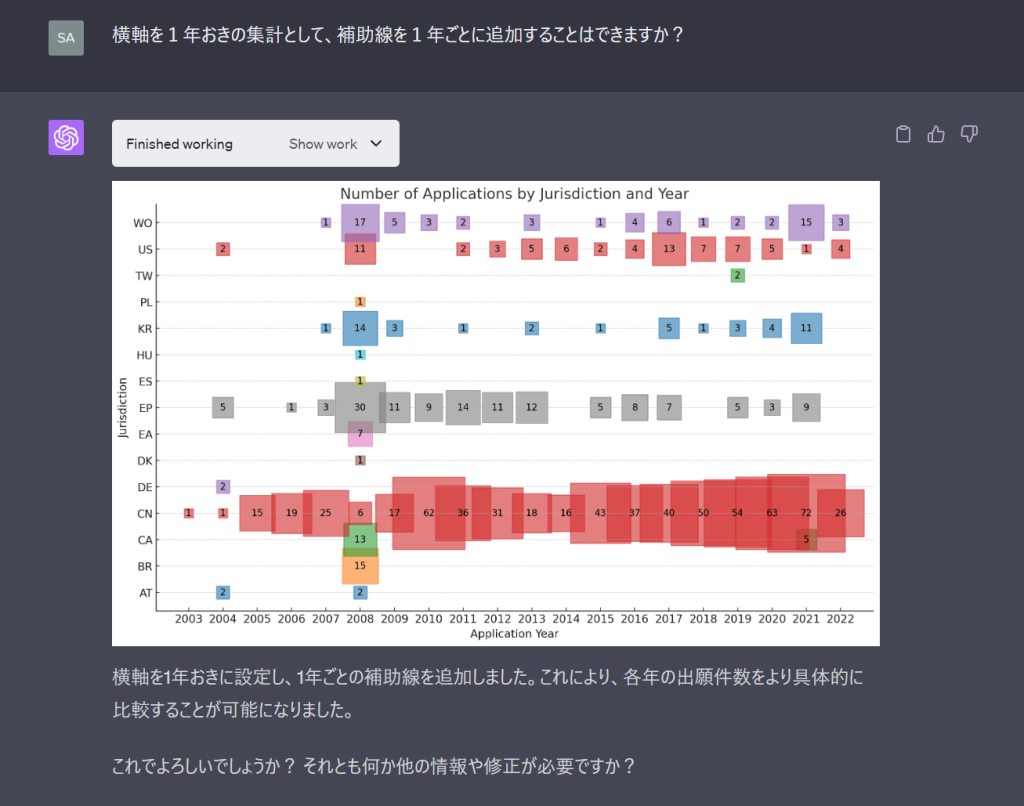
社内用の分析なら十分すぎるクオリティです。付き合いのあるクライアントさんなら社外にでも出せそうなクオリティで出願年×出願国の動向のマトリックスバブルチャートができました。
ここまでの作業は5分弱。正直言ってこんなに簡単に分析できるようになるとは想像してませんでした。ツールの進化は本当に素晴らしいですね。
しかも、ここでは試していませんが画像のパワーポイントへの出力やデータのエクセルへの出力などもできるそうです。
問題点を挙げると、このツールの基本的な問題として現時点では分析した内容は学習されるはずなので守秘義務のあるような内容について分析しないほうがよいでしょう。
また、データが正しく集計されているかは分かりませんので、抜き取り検査的に集計結果を検証する必要もあるかもしれません。この機能で対応可能なデータサイズの問題もありでしょうからあまり大規模なデータの分析は難しいかもしれません。
実を言うとChatGPTでネットにアクセスして情報を持ってこさせることで以前から似たようなことができるWebブラウズ機能や他のプラグイン機能は主流にならないだろうなと感じていました。というのもTwitterがツイートの表示回数の制限をしたようにネットサービス各社は外部の自動処理サービスを遮断することが多々あります。その意味で使う気はあまりなかったのですが今回の機能は手元のデータをアップロードして処理してもらうので、このような問題もありません。
また、自前のデータでこういう処理ができるのは本当に価値があります。しかもここでは作ったpythonのプログラムを出力することもできるので、これを取得し自前のサーバで走らせれば秘密情報の漏洩のリスクが殆どなくなるのもよいと感じました。
今回は1000件程度で比較的集計しやすい出願年や出願国のデータについて分析しましたので、分析が難しくなるIPCや出願人などが入る大規模のデータを適切に分析できるかはまだ分かりません。しかし可能性はかなり感じました。
また、上述の通り手元のデータを使って非公開で処理をする仕組みも作れそうなので、うまく使えば、調査用検索式の作成、発明発掘、明細書の叩き台作成などにも活用できそうだと期待を感じました。
便利なツールなのでぜひ使い倒して行きたいですね。