テキスト処理関数の使用例(複数の特許分類から複数の上位階層の分類への変換)
エクセルの特許情報分析への適用について引き続き研究をしているのですが、配列と新しい関数を使うといろいろな場面で効率化ができそうな方法を編み出したので紹介します。
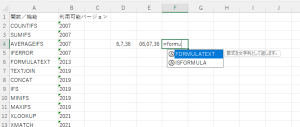
なお、ここで紹介した数式はTEXTSPLIT関数を使っているので今はMicrosoft365でのみ利用可能です。
通常の特許データベースでダウンロードしたCSVでは、1件の出願に付与された複数の特許分類が所定の区切文字で区切られた状態で1つのセルに含まれたデータとなっています(A3セル参照)。しかし、このようなデータでは分析がしづらく、ピボットテーブルで分析するために1セル1分類となるようにデータを分割して重複のあるデータを作成したり、セルに含まれる一部の文字を探すように数式を作り検索したりすることが行われます。
また、特許分類を分析するときの難しさとして、特許分類は技術を複数階層に分けて分類しているため、ダウンロードしたデータに含まれるコードの説明をそのまま読んでも何に関する技術であるかわからない場合もあり、上位階層のコードの説明を併記するなどの工夫が必要になります。
そこで、ダウンロードされた特許分類のデータについて、上位階層のコードを1セル1階層になるように加工する数式を作成しました。具体的な処理は画像のコメントの通りですが、1つのセルで配列機能を使いながら分けたり所定の処理をしたうえでつなげたりすることで、上位階層の特許分類のコードに変換しています。これを適用することで、多数の下位階層のコードから多数の上位階層のコードのリストを作成できます。ローマ字の昇順で並べ替えもしているのでコードの見落としのリスクも低くなります。
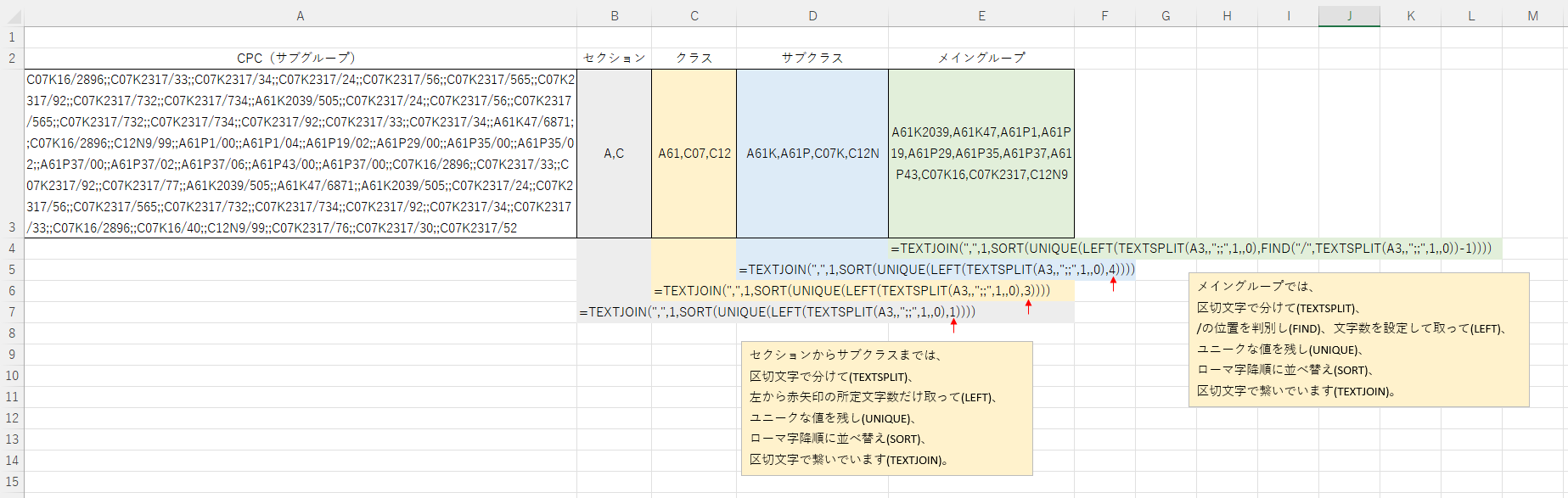
※上記の数式にならって、お持ちのデータの仕様に応じて適宜修正しながら数式を作成すればみなさんも同じように処理ができます
このように処理してから分析に使ってもいいですし、また、自社分野に関する分類ならコードを見れば何か分かると思うので、この処理だけで効率化できるかも知れません。
さらに、コードごとの説明の一部に置き換えて表示したり、コード+説明冒頭数文字のような形に置き換えることもできますし、応用の幅は広いと思います。セミナーで教えるのによい便利な手法が確立できました。
以上の内容を含めて弊所では様々な特許情報分析の手法を用意しています。分析手法に関するセミナーや分析プロジェクトのご相談などありましたら、管理人の特許事務所のページからお知らせください。